|
Курсовая работа: Модель распределенияКурсовая работа: Модель распределения
Курсовая работа по статистике Работу выполнил ст. гр. ЭР-6-4 Шалыгин Д.А. Московский государственный технологический университет «Станкин» Кафедра «Производственный менеджмент» Москва 2001 Раздел 1. Исследование модели распределения1. Формирование выборочной совокупности Обычно бывает затруднительно исследовать генеральную совокупность. Тогда проводят исследование выборочной совокупности, и его результаты распространяют на генеральную совокупность. Наиболее часто для формирования выборочной совокупности применяют бесповторную случайную выборку. Случайный отбор организуют с помощью жребия, таблицы случайных чисел или программы, генерирующей квазислучайную последовательность чисел. Для этого единицы генеральной совокупности нумеруют. Данные, соответствующие выпавшим, номерам попадают в выборку. При этом повторяющиеся номера пропускаем. Покажем применение таблицы случайных чисел. В табл. 1 приложения приведено пятьсот четырехзначных случайных чисел. Рассмотрим пример получения выборки. Генеральная совокупность содержит значения восьми количественных экономических показателей для 100 предприятий. Она представлена в табл.2 приложения. Наиболее проработанной в статистике является парная корреляция. Положим, нужно установить корреляционную связь между двумя показателями. В нашем случае мы изучаем связь между годовой балансовой прибылью (показатель 5) и электровооруженностью на одного работающего (показатель №7), выбираем в табл.1 приложения четырёхзначное число из 7-го столбца, 5-ой строки; т.к. сумма номеров показателей чётна, то из него берём правую половину; далее выбираем 30 неповторяющихся чисел. Затем из табл.2 приложения выбираем в соответствующих номерах строк 30 пар значений изучаемых показателей, в соответствии с этими данными получаем табл.1.1 Таблица 1.1
2. Построение интервального ряда распределения Этот и последующие этапы работы в этом разделе выполняем для каждого изучаемого признака в отдельности.
Принимая во внимание, что выборочная совокупность содержит n значений, величину равных интервалов выбираем по формуле Г.А. Стерджесса: где К = 1+3,322gn- число интервалов; при n=30 К=5. xmax и xmin - минимальное и максимальное значения признака. Определяем границы интервалов. Для первого интервала левая граница равна xmin, а правая – xmin +i и, для второго, соответственно - xmin +i и xmin +2i и т.д. Строим таблицу частоты распределения значений признака по интервалам и гистограмму. Для определенности считаем, что значение признака, лежащее на границе двух интервалов, попадает в правый интервал. Для показателя x: Определяем границы интервалов и строим таблицу частоты распределения значений признака по интервалам:
Строим гистограмму: Для показателя y: Определяем границы интервалов и строим таблицу частоты распределения значений признака по интервалам:
Строим гистограмму: 3. Проверка соответствия эмпирического распределения нормальному закону распределения Для проверки соответствия эмпирического распределения случайной величины нормальному закону распределения в нашем случае (при n<30) можно использовать критерии Шапиро-Уилкса (W) и Колмогорова (D). В нашем случае мы используем критерий Колмогорова.
Сначала определим среднюю величину
Вычисляем ошибку определения средней по выборочной совокупности (ошибку выборки):
где n - численность выборки; N= 100 - численность генеральной совокупности; t - коэффициент доверия; при доверительной вероятности 95,45% t=2.
Для признака x:
Для признака y: Генеральная средняя располагается в следующих границах: Определяем эти границы:
Ранжируем значения величин x и y по возрастанию (табл.1.2.): x1£ x2 < …£ xn-1£ xn Таблица 1.2.
Перейдем к нормированным значениям аргумента (табл.1.3): Таблица 1.3.
Принимаем значения эмпирической функции распределения в точке t равным следующему значению (табл.1.4):
где i= 1, 2,...,n. При t< t1 F*(t)=0, а при t>tn F*(t)=l. Таблица 1.4.
Определим максимальное значение модуля разности между эмпирической функцией распределения F*(t) и теоретической функцией для нормального закона распределения F(t) (значения F(t) представлены в табл.3.2):
и определяем величину:
Затем по таблице определяем в зависимости от l вероятность Р(l), того что за счёт чисто случайных причин расхождение между F*(t) и F(t) будет не больше, чем фактически наблюдаемое. При сравнительно больших Р(l) теоретический закон распределения можно считать совместимым с опытными данными. Раздел 2. Исследование взаимосвязи двух количественных признаков 1. Оценка тесноты корреляционной связи Из логических соображений выдвинем предположение, что признак (названный нами y) зависит от второго исследуемого признака x. Используя проведенное в первом разделе разбиение значений x на интервалы, построим аналитическую таблицу: Аналитическая таблица исследования зависимости признака y от признака x
Далее рассчитываем общую дисперсию:
где
Оценку тесноты связи признаков y и x проводим по шкале Чеддока: -если 0,3<h£0,5, то теснота связи заметная; -если 0,5<h£0,7, то теснота связи умеренная; -если 0,7<h£0,9, то теснота связи высокая; -если 0,9<h£0,9(9), то теснота связи весьма высокая.
2. Определение формы связи двух признаков Примерное представление о виде зависимости y от x даёт линия, проведённая через точки,
соответствующие групповым средним и полученные на основе аналитической таблицы
следующим образом: среднему значению признака
Вычислив частные производные и приравняв их к нулю, получим систему линейных алгебраических уравнений относительно коэффициентов а и b. В нашем случае система уравнений имеет вид:
Решая эту систему уравнений относительно b, получим:
Решая первое уравнение относительно а, получим:
Линейный коэффициент корреляции равен: где sx и sy - средние квадратические отклонения признаков x и y.
Рассчитаем общую дисперсию:
где yx(хi) - значение величины y, рассчитанное по уравнению регрессии при подстановке в него значения xi; yi- значение величины y в исходной таблице, соответствующее значению xi.
Определим индекс корреляции:
Индекс корреляции принимает значения 0£ i £1.
Т.к. i близок к единице, то связь между признаками хорошо описана выбранным уравнением регрессии. Для линейной зависимости дополнительным условием для такого заключения является близость значений r и i.
Можно выбрать несколько видов уравнения регрессии. Наилучшим из них будет то уравнение, которому соответствует меньшая средняя квадратическая ошибка уравнения регрессии: где m - число коэффициентов в уравнении регрессии.
Принимая во внимание то, что мы имеем дело с малой выборкой, необходимо оценить значимость коэффициентов уравнения регрессии, а также индекса корреляции i и линейного коэффициента корреляции r. Значимость линейного коэффициента корреляции r оцениваем с помощью критерия Стьюдента. Фактическое значение критерия Стьюдента равно:
Критическое (предельное) значение критерия Стьюдента tk, берем из табл.4 приложения, задаваясь уровнем значимости a=5,0 и имея число степеней свободы равное:
k=n-2 Если tr>tk, то величину линейного коэффициента корреляции считаем значимой и можем использовать в расчетах.
Значимость коэффициентов уравнения регрессии а и b также оцениваем с помощью критерия Стьюдента. Расчетные значения критерия Стьюдента равны:
Учитывая, что число степеней свободы также равно k=n-2, сравнение фактических значений критерия Стьюдента ведем с уже найденным критическим значением tk. Если ta>tk, tb>tk, то соответствующий коэффициент уравнения регрессии значим, и мы можем им пользоваться. Значимость индекса корреляции определяем с помощью критерия Фишера. Фактическое значение критерия Фишера равно:
где m - число коэффициентов в уравнении регрессии.
Табличное значение критерия Фишера Fk; определяется по табл.5 приложения, задаваясь уравнением значимости a и числом степеней свободы k1=m-l; k2=n-m.
Если Fi>Fk, то величину индекса корреляции считаем значимой и можем ее использовать в расчетах. Если коэффициенты а и b, а также линейный коэффициент корреляции r и индекс корреляции i значимы, то все наши расчеты и выводы, опирающиеся на эти величины, правомерны и мы можем использовать полученное уравнение регрессии для прогноза. Ошибка прогноза будет зависеть, в частности, от остаточной дисперсии s2e. Раздел 3. Изучение динамических рядов 1. Изучение сезонных явлений Исследуем сезонные процессы в наших двух динамических рядах. При изучении сезонных явлений из уровней динамического ряда целесообразно вычесть значения, получаемые по уравнению тренда, которые отражают основную тенденцию развития.
где k=1; j=1. Для нахождения коэффициентов a0, aj, bj применяем метод наименьших квадратов.
Для признака x: Для признака y:
Обычно для расчётов используют ежемесячные данные за один год или несколько лет. В этом случае интервал между двумя соседними месяцами принимают равным: Построив модель сезонных колебаний, положим для уточнённого изучения основной тенденции a0 =0. Исключим сезонные колебания из уровней динамического ряда (табл.3.1.1). Таблица 3.1.1
2. Определение основной тенденции развития Для выявления основной тенденции развития применяют аналитическое выравнивание. В результате выравнивания получают зависимость изучаемого показателя от времени, т.е. трендовую модель. Используем линейную трендовую модель:
Наиболее тщательно выбирают модель для целей экстраполяции значений показателя. Значение х и у выбираем из табл.6 приложения. Коэффициенты уравнения определяем методом наименьших квадратов. В нашем случае система уравнений относительно коэффициентов a0 и a1 имеет вид:
Для признака x:
Для признака y:
3. Изучение корреляционной зависимости между уровнями двух динамических рядов Продолжаем рассмотрение двух выбранных нами рядов динамики. При исследовании тесноты связи между их уровнями на первое место выступает анализ смысла связи между рядами и установление факторного и результативного признаков. Без такого анализа значение коэффициента корреляции может выражать только случайное сопутствие в изменении уровней двух рядов. Применение традиционных приемов изучения корреляции к динамическим рядам сопряжено со следующими особенностями: 1. В социально-экономических рядах динамики имеет место тенденция, вызванная действием постоянных факторов: последующие уровни рядов динамики зависят от последующих, т.е. имеется автокорреляция и авторегрессия. Это говорит о том, что нарушена одна из предпосылок применения теории корреляции - независимость отдельных наблюдений друг от друга. Если автокорреляцией при этом пренебречь, то полученная зависимость будет отражать взаимосвязь, которой в действительности не существует, или искажать реально существующую взаимосвязь. 2. Второй особенностью изучения корреляции динамических рядов является наличие временного лага, т.е. сдвига по времени изменения уровней одного ряда по отношению к изменению уровней другого ряда. Если сдвинуть уровни одного ряда относительно другого и убрать временной лаг, то получим верную оценку тесноты корреляционной связи уровней двух динамических рядов. 3. Третьей особенностью является изменение тесноты корреляционной связи уровней динамических рядов со временем. Вначале устраняем временной лаг, значение которого определяем графически или подбором; с расчетом коэффициента корреляции. Затем приступаем к исследованию взаимосвязи уровней. Существует четыре направления изучения корреляционной зависимости между уровнями двух динамических рядов: - коррелирование уровней; - коррелированно разностей; - коррелирование остатков (отклонений от трендов); - коррелирование с учетом фактора времени. 3.1. Изучение корреляционной зависимости между уровнями двух динамических рядов методом коррелирования уровней Нам следует построить уравнение авторегрессии для каждого из изучаемых динамических рядов, проверив наличие временного лага:
где L – величина временного лага (L=1).
Для динамического ряда xi:
Т.к. полученные коэффициенты корреляции больше табличного, то переходим к следующему методу. 3.2. Изучение корреляционной зависимости между уровнями двух динамических рядов методом коррелирования разностей По первоначальным динамическим рядам xi, yi с количеством членов n строим новые динамические ряды ui, wi с количеством членов n-1(табл.3.2.1), где:
Таблица 3.2.1
Далее считаем автокорреляцию для динамических рядов u и w: Для динамического ряда ui:
Для динамического ряда wi:
Т.к. полученные коэффициенты корреляции больше табличного, то переходим к следующему методу. 3.3.Изучение корреляционной зависимости между уровнями двух динамических рядов методом коррелирования остатков (отклонений от трендов) В данном случае зависимость ищется в виде eyi=f(exi), где:
Значения Таблица 3.3.1
Т.к. полученные коэффициенты корреляции опять больше табличного, то переходим к следующему методу. 3.4. Изучение корреляционной зависимости между уровнями двух динамических рядов методом коррелирования с учётом фактора времени
Тогда система уравнений, полученная методом наименьших квадратов имеет следующий вид:
Необходимо отметить, что в этом методе коэффициент автокорреляции не исследуется. Решение системы уравнений методом Гаусса, все необходимые данные в табл.3.4.1: Таблица 3.4.1
Далее определяем индекс корреляции:
где yx(xi) – значение величины y, рассчитанное по уравнению регрессии при подстановке в него значений xi и ti; yi – значения y из исходной таблицы.
Значимость индекса корреляции определяем с помощью критерия Фишера, фактическое значение критерия Фишера равно:
Табличное значение критерия Фишера определяем по табл.5 приложения, задаваясь уравнением значимости a и числом степеней свободы k1=m-1; k2=n-m.
Если то величину индекса корреляции считаем значимой. Определим коэффициент детерминации:
Следовательно, величина y зависит от величин x и t на 98,01%. Остальные 1,99% - это зависимость величины y от неучтённых величин. Подводя итог необходимо отметить, что в исследовании методом коррелирования динамических рядов, с учётом фактора времени была определена весьма высокая теснота связи, равная 0,9900; величина коэффициента детерминации равная 0,9801 говорит о том, что величина y зависит от величин x и t, включённых в уравнение, на 98,01%, все остальные 1,99% - это зависимость величины y от неучтённых величин. |
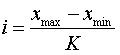
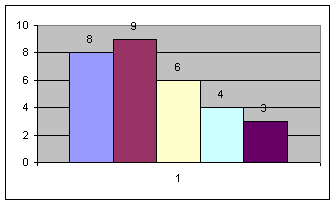
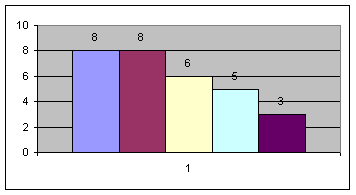
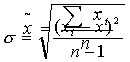
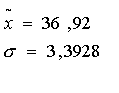 Для признака x:
Для признака x: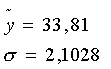 Для признака y:
Для признака y: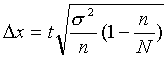
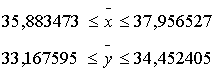
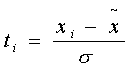
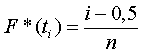
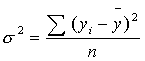
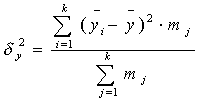 где
где 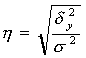 Для оценки тесноты связи между признаками y и x рассчитываем корреляционное
отношение:
Для оценки тесноты связи между признаками y и x рассчитываем корреляционное
отношение: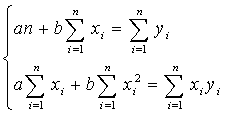
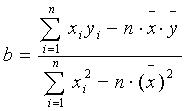
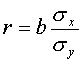
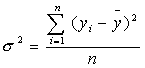
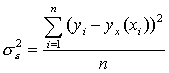 и остаточную дисперсию:
и остаточную дисперсию: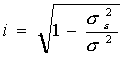
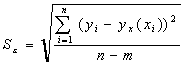
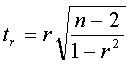
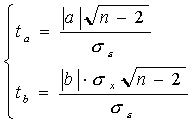
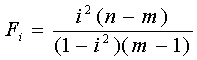
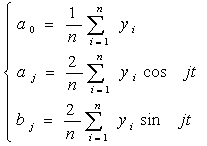 Получаем:
Получаем: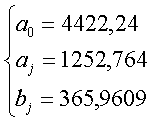
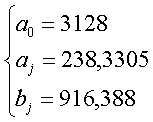
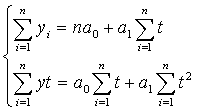
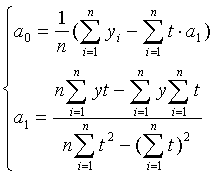 и
коэффициенты a0 и a1 равны:
и
коэффициенты a0 и a1 равны: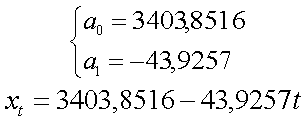
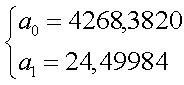
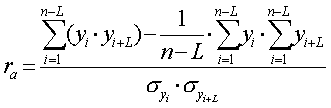
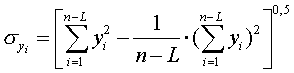
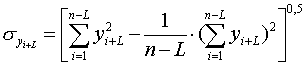
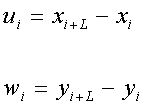
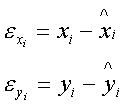
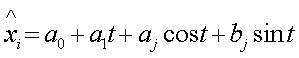
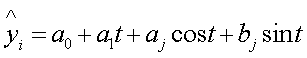
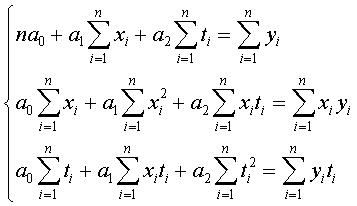
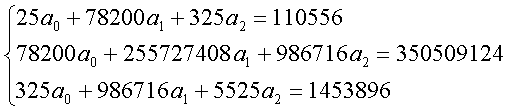
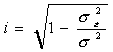
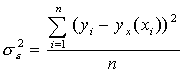
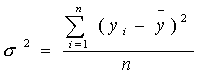
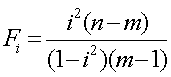
|
|
| 17.06.2012 |
| Большое обновление Большой Научной Библиотеки |
| 12.06.2012 |
| Конкурс в самом разгаре не пропустите Новости |
| 08.06.2012 |
| Мы проводим опрос, а также небольшой конкурс |
| 05.06.2012 |
| Сена дизайна и структуры сайта научной библиотеки |
| 04.06.2012 |
| Переезд на новый хостинг |
| 30.05.2012 |
| Работа над улучшением структуры сайта научной библиотеки |
| 27.05.2012 |
| Работа над новым дизайном сайта библиотеки |